Le Protocole Http
A - La communication entre client et serveur
La compréhension des échanges, ayant lieu entre un client et un serveur Web lors de la consultation d’un site, est essentielle. Il s’agit d’un mécanisme de type requête/réponse.
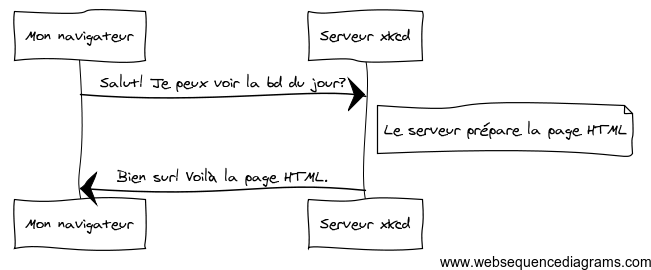
- L’échange est initié par le client, qui envoie au serveur une requête pour consulter une ressource Web.
- Le serveur prépare la page HTML associée.
- Le serveur renvoie la page HTML au client, qui l’affiche.
Afin de se comprendre, client et serveur Web utilisent pendant leurs échanges un protocole commun : HTTP.
B - Anatomie d’une requête HTTP
1 - Une requête standard
HTTP (HyperText Transfert Protocol) est le protocole de transfert du Web. C’est son invention en 1989 au CERN de Genève, en même temps que le langage HTML, qui a conduit à l’apparition du World Wide Web : un immense réseau de réseaux, où on peut “rebondir” d’une page Web à une autre en utilisant des liens sans avoir besoin de connaître l’emplacement physique des serveurs et des ressources consultés.
HTTP est fondamentalement un protocole très simple, basé sur des commandes textuelles.
Prenons comme exemple la première étape de l’échange décrit plus haut.
La requête HTTP envoyée par le navigateur prend une forme similaire à celle-ci :
GET / HTTP/1.1
Host: xkcd.com
Accept: text/html
User-Agent: Mozilla/5.0 (Macintosh)
La première ligne de cette requête HTTP est la plus importante. Elle contient :
- La méthode associée à la requête : ici, GET signifie une demande de ressource.
- L’identifiant de la ressource concernée. Ici, / (symbole de la racine, comme sous Linux) indique qu’on souhaite accéder au document par défaut.
- La version du protocole HTTP, ici 1.1.
Les autres lignes de la requête HTTP sont appelés champs d’en-tête (HTTP header fields ou plus simplement headers).
La plupart des applications n’utilisent que quelques en-têtes HTTP :
Referer: savoir d’où viennent les clients ;Cookie: pour récupérer les cookies ;User-Agent: pour savoir quel navigateur les utilisateurs utilisent ;X-Forwarded-For: pour obtenir l’adresse IP source (même si ce n’est pas la meilleure méthode pour le faire).
D’autres en-têtes HTTP sont principalement utilisés par le serveur Web, vous pouvez également trouver des failles de sécurité dans leur gestion. Cependant, vous êtes moins susceptible de trouver un bogue dans un serveur Web que dans une application Web.
L’un des en-têtes les plus importants est Host. Le Host header est principalement utilisé par le serveur Web pour savoir à quel site Web, vous essayez d’accéder. Lorsque plusieurs sites Web sont hébergés sur le même serveur, le serveur Web utilise cet en-tête pour effectuer l’hébergement virtuel : même si vous vous connectez toujours à la même adresse IP, le serveur lit les Host informations et fournit le bon contenu en fonction de cela. Si vous mettez l’adresse IP dans l’en-tête Host ou un nom d’hôte invalide, vous pouvez parfois obtenir un autre site Web et obtenir des informations supplémentaires à partir de celui-ci.
De nombreuses méthodes HTTP existent :
- La méthode
GET: pour demander du contenu, c’est la requête la plus courante envoyée par les navigateurs ; - La méthode
POST:POSTest utilisé pour envoyer une plus grande quantité de données ; il est utilisé par la plupart des formulaires et également pour le téléchargement de fichiers. - La méthode
HEAD: la méthodeHEADest très similaire à la requêteGET, la seule différence est dans la réponse fournie par le serveur, la réponse ne contiendra que les en-têtes et aucun corps.HEADest massivement utilisé par les araignées Web pour vérifier si une page Web a été mise à jour sans télécharger le contenu complet de la page. - Il existe de nombreuses autres méthodes HTTP :
PUT,DELETE,PATCH,TRACE,OPTIONS,CONNECT… Vous pouvez en savoir plus à leur sujet sur la page Wikipédia .
2 - une requête paramétrée
Les paramètres sont une autre partie importante de la demande. Lorsqu’un client accède à la page
http://vulnerable/article.php?id=1&name=2 , la requête suivante est envoyée au serveur Web :
GET /article.php?id=1&name=2 HTTP/1.1
Hôte : vulnerable
User-Agent : Mozilla Firefox
Les requêtes POST sont vraiment similaires, mais à la place, les paramètres sont envoyés dans le corps de la requête. Par exemple, le formulaire suivant :
<html>
[...]
<body>
<form action="/login.php" method="POST">
<label for="log">Nom d’utilisateur :</label>
<input type="text" id="log" name="log">
<label for="mdp">Mot de passe :</label>
<input type="password" id="mdp" name="mdp" value="">
<input type="submit" value="Submit">
</form>
</body>
</html>
Une fois le formulaire rempli avec les valeurs suivantes :
- nom d’utilisateur, ’admin’,
- le mot de passe, ’mot de passe123’.
Et après avoir été soumis, la requête suivante est envoyée au serveur
POST /login.php HTTP/1.1
Hôte : vulnérable
User-Agent : Mozilla Firefox
Contenu-Longueur: 35
log=admin&mdp=mot de passe123
3 - Cryptage des informations
Si la balise form contient un attribut enctype="multipart/form-data", la requête envoyée sera différente :
POST /upload/example1.php HTTP/1.1
Host: vulnerable
Content-Length: 305
User-Agent: Mozilla/5.0 [...] AppleWebKit
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryfLW6oGspQZKVxZjA
------WebKitFormBoundaryfLW6oGspQZKVxZjA
Content-Disposition: form-data; name="image"; filename="myfile.html"
Content-Type: text/html
My file
------WebKitFormBoundaryfLW6oGspQZKVxZjA
Content-Disposition: form-data; name="send"
Send file
------WebKitFormBoundaryfLW6oGspQZKVxZjA--
Nous pouvons voir qu’il y a un en-tête Content-type différent : Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryfLW6oGspQZKVxZjA.
Le " Webkit" provient d’un navigateur basé sur Webkit ; d’autres navigateurs utiliseront à la place une longue chaîne aléatoire. Cette chaîne est répétée pour chaque partie des informations multipartites. La dernière partie contient la chaîne suivie de –.
4 - Utilisation de tableaux
Il est également possible d’envoyer des paramètres sous forme de tableau (ou de hachage selon l’analyse effectuée côté serveur).
Vous pouvez par exemple utiliser : /index.php?id[1]=0 pour encoder un tableau contenant la valeur 0.
Cette méthode d’encodage est souvent utilisée par les frameworks pour effectuer un mappage automatique des requêtes vers
les objets. Par exemple, la requête suivante : user[name]=louis&user[group]=1 sera mappée sur un objet User avec
l’attribut name égal à louis et l’attribut group mappé sur 1. Cette cartographie automatique peut parfois être
exploitée à l’aide d’attaques nommées mass-assignation.
En envoyant des paramètres supplémentaires, vous pouvez, si l’application ne s’en protège pas, modifier des attributs
dans l’objet récepteur. Dans notre exemple précédent, vous pouvez par exemple ajouter user[admin]=1 à la demande et voir si votre utilisateur obtient des privilèges d’administrateur.
C - Anatomie d’une réponse HTTP
Lorsqu’il reçoit une requête HTTP, le serveur Web y puise les informations nécessaires pour construire la réponse, puis la renvoie au client. Continuons avec notre exemple précédent.
La réponse HTTP renvoyée du serveur au client prend l’aspect ci-dessous.
HTTP/1.1 200 OK
Date: Mon, 14 Apr 2013 14:05:05 GMT
Server: lighttpd/1.4.19
Content-Type: text/html
<html>
<!-- code HTML de la page -->
<!-- ... -->
</html>
La première ligne de la réponse contient son statut sous la forme d’un code qui indique le résultat de la requête. Comme une requête, une réponse HTTP contient des champs d’en-tête (Date, Content-Type et bien d’autres) permettant de véhiculer des informations additionnelles. Par exemple, il est possible d’utiliser certains champs pour mettre en place un mécanisme de cache.
Enfin, la réponse HTTP contient éventuellement la ressource demandée par le client. Le plus souvent, il s’agit d’une page Web décrite sous la forme de balises HTML.
D - Les codes HTTP
Les codes de retour HTTP peuvent être classés par familles en fonction du premier chiffre.
| Famille | Signification | Exemples |
|---|---|---|
| 1xx | Information | |
| 2xx | Succès | 200 : requête traitée avec succès |
| 3xx | Redirection | |
| 4xx | Erreur provenant du client | 400 : syntaxe de la requête erronée 404 : ressource demandée non trouvée |
| 5xx | Erreur provenant du serveur | 500 : erreur interne du serveur503 : service temporairement indisponible |

Vous trouverez sur Wikipédia plus de détails sur le protocole HTTP.
E - Le HTTP sécurisé
HTTPs est simplement HTTP effectué au-dessus d’un Secure Socket Layer (SSL). La partie SSL assure au client que :
- Il parle au bon serveur : authentification ;
- La communication est sécurisée : cryptage.
Plusieurs versions de SSL existent avec certaines d’entre elles considérées comme faibles (SSLv1 et SSLv2).
SSL peut également être utilisé pour garantir l’identité du client. Les certificats clients peuvent être utilisés pour garantir que seules les personnes disposant de certificats valides peuvent se connecter au serveur et envoyer des demandes. C’est un excellent moyen de limiter l’accès à un service et est souvent utilisé pour les systèmes nécessitant un niveau de sécurité élevé (passerelle de paiement, service web sensible). Cependant, la maintenance des certificats (et des listes de révocation) peut être pénible pour les grands déploiements.